参数配置
日常进行数据开发的过程中,为了使任务自动周期运行时能动态适配环境变化,离线开发提供了参数配置的功能,参数的应用场景十分广泛。例如在同步任务中将增量数据写入Hive表的天分区,需要在分区填写栏支持根据天变化的时间变量;例如在多个Spark SQL任务中需要用到公司统一规定的常量...多个场景都会利用到参数配置的功能。
参数配置可分为「运行参数」和「任务上下游参数」两大类,「运行参数」又可分为「自定义参数」和「全局参数」两类。
1、运行参数
自定义参数
生效范围:当前任务内。
在「任务参数->运行参数」,点击「添加运行参数」按钮,可以添加自定义参数,如下图所示:

在任务中通过“${参数名称}”进行参数声明,然后将其配置在右侧「运行参数」列表中,任务运行时实际会在代码中参数位置使用其实际值进行替换。
例如,在「运行参数」中设置自定义参数,"batchworks1=1","batchworks2=value",如下图所示
其中,“1”和“value”是两个常量字符串,任务运行时可进行参数替换。

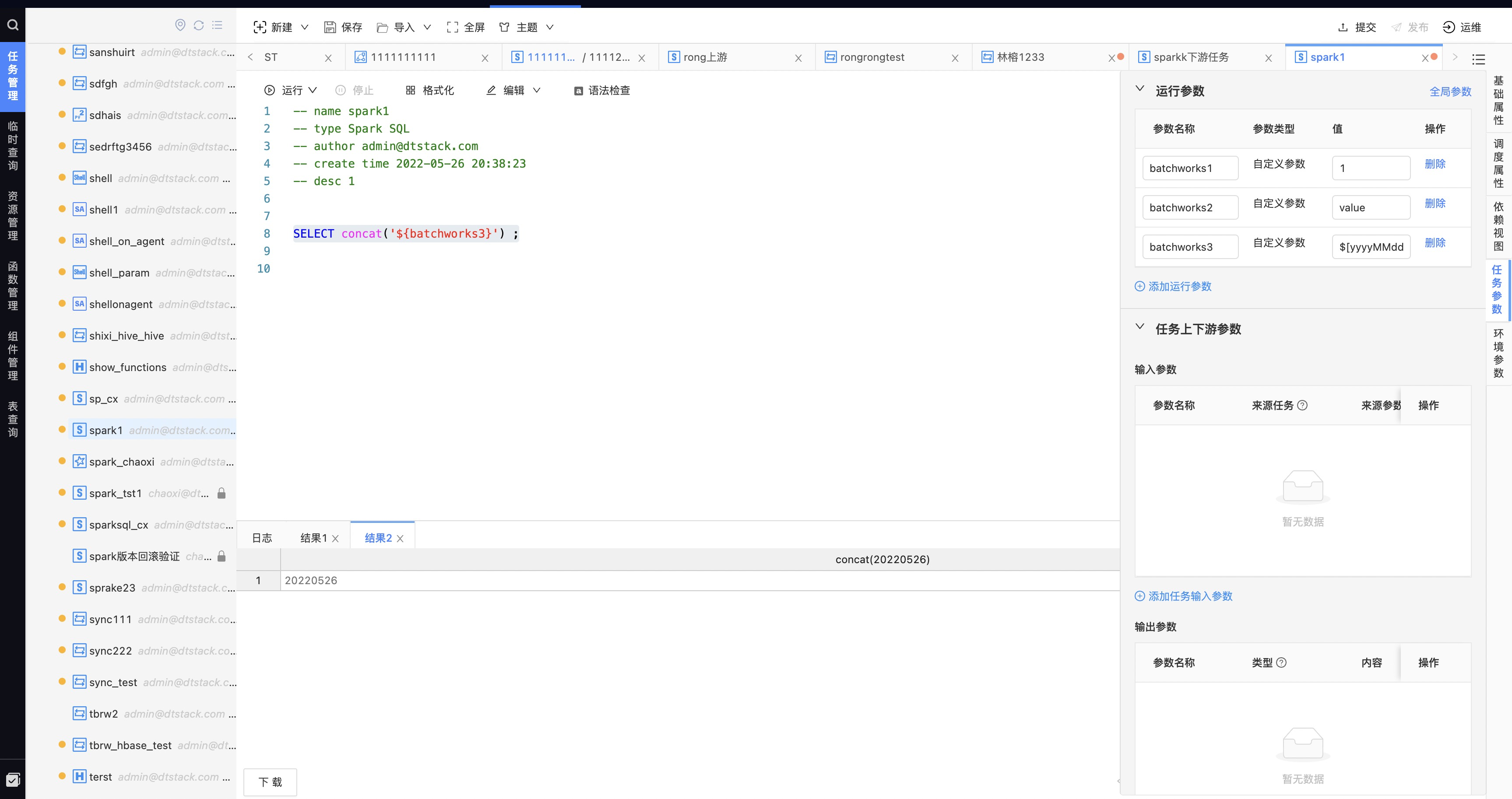
在「运行参数」中,设置自定义参数"batchworks3=$[yyyyMMdd]",自定义参数按照一定的规则填写,可基于时间进行取值,如下图所示:
 )
)
假设今天是2022年5月26日,在右侧面板设置参数值${yyyyMMdd},在任务运行时,${batchworks3}参数即可被替换为20220526;
全局参数
生效范围:平台内所有租户产品项目下所有任务。
如何配置全局参数
超级管理员和控制台管理员可以在「控制台 -> 全局配置 -> 全局参数管理」中进行配置,如下图
 )
)
全局参数中,包含默认存在的系统参数和可自定义的全局参数。
离线开发自带如下几个系统参数:
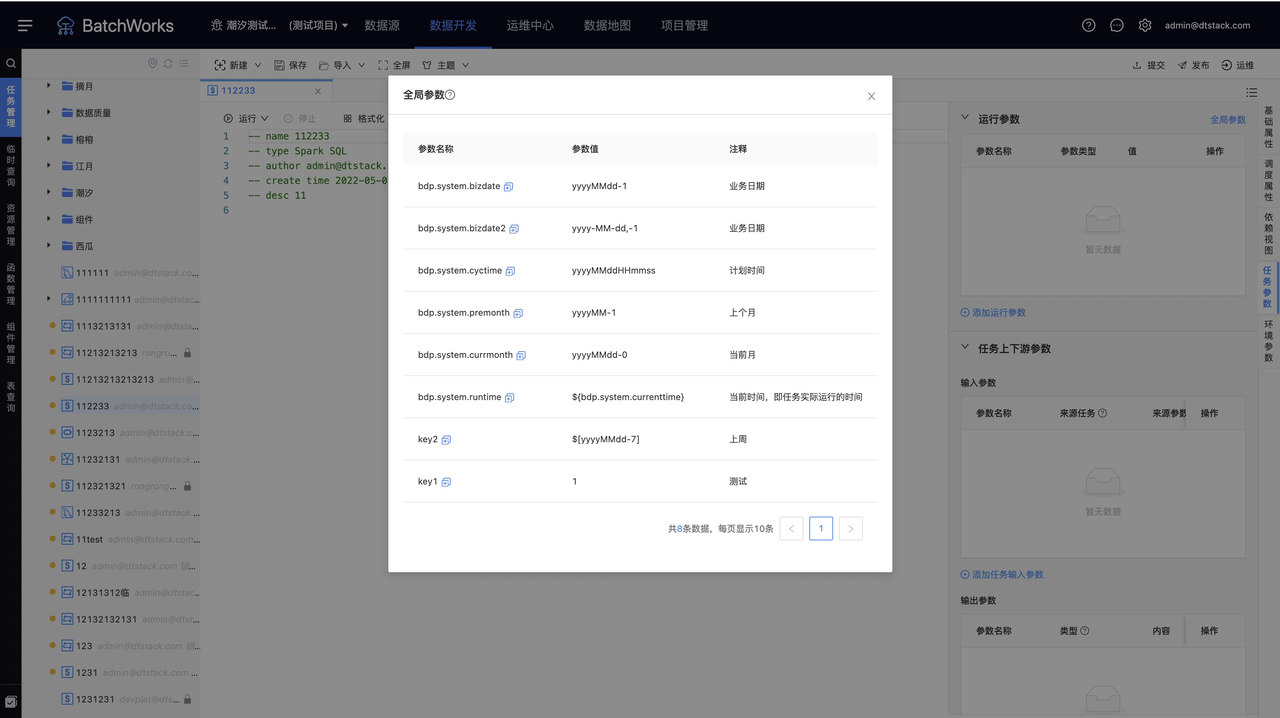
${bdp.system.bizdate} --业务日期,业务日期默认为计划运行日期的前一天,格式:yyyyMMdd
${bdp.system.bizdate2} --业务日期,格式:yyyy-MM-dd
${bdp.system.cyctime} --计划时间,格式:yyyyMMddHHmmss
${bdp.system.premonth} --上个月(以计划时间为基准),格式:yyyyMM
${bdp.system.currmonth} --当前月(以计划时间为基准),格式:yyyyMM
${bdp.system.runtime} --当前时间,即任务实际运行的时间,格式:yyyyMMddHHmmss
定时运行时间,不是任务实际开始运行的时间,若设置了每天02:00开始运行,但此时系统资源不足,则任务会延迟执行,假设任务在02:12开始实际运行,但上述几个参数的取值基准依然为02:00
自定义全局参数配置如下图
 )
)
参数值支持填写常量,例如“1”,也可以支持填写变量“${yyyy-MM-dd}”,更多填写方式请参考“更多使用技巧”
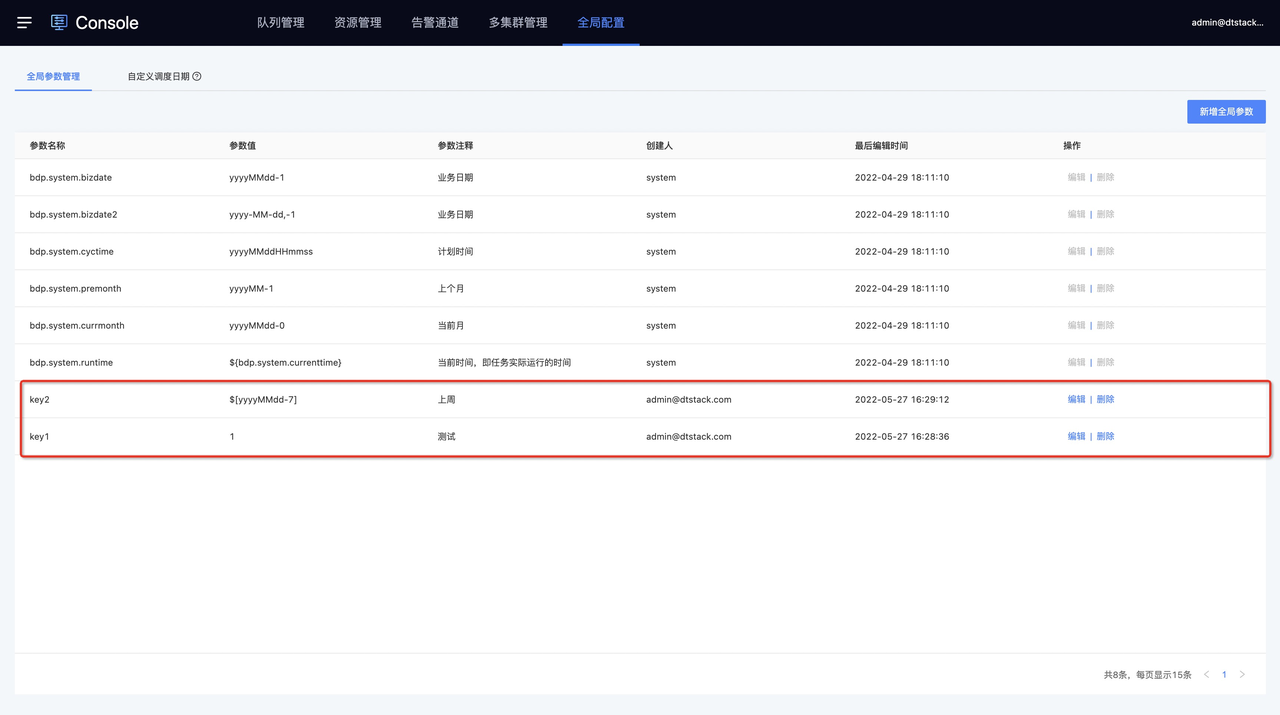
如下图所示,分别设置了常量全局参数“key1=1”,变量全局参数“key2=$[yyyyMMdd-7]”
如何引用全局参数
在「离线开发 -> 数据开发 -> 任务参数 ->运行参数」中,存在「全局参数」按钮,如下图所示
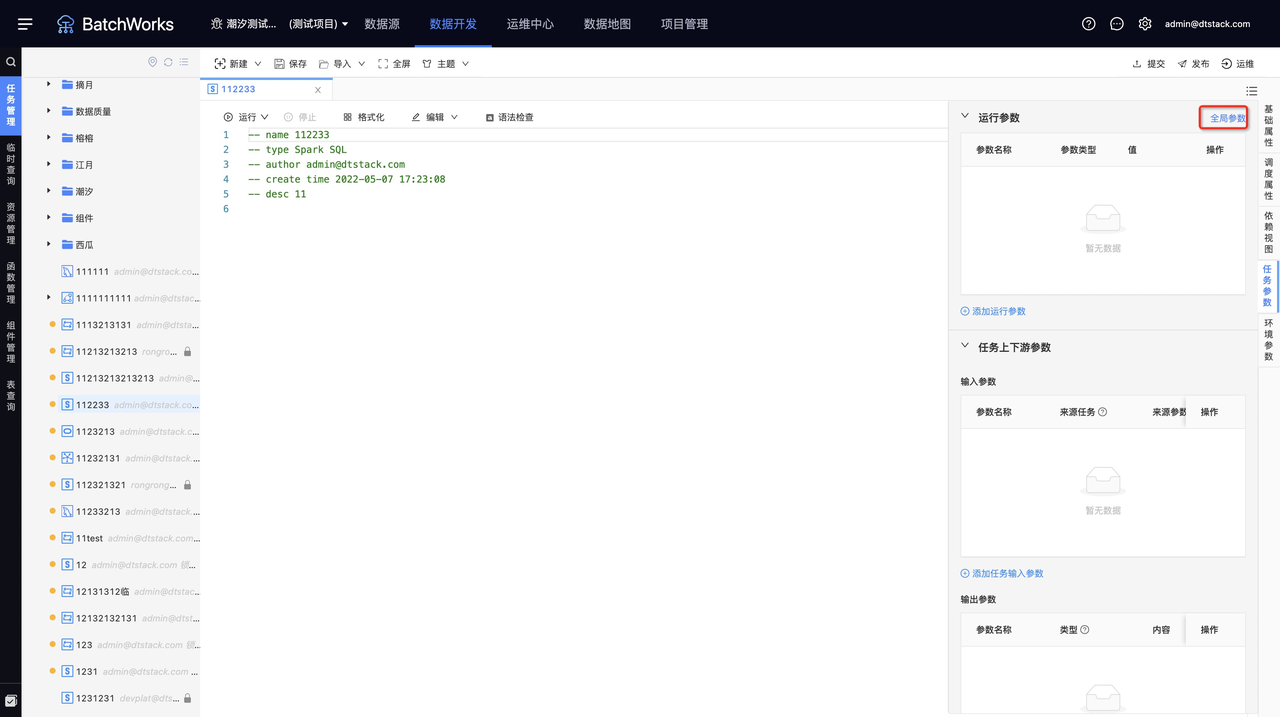
点击「全局参数」按钮,可以查看控制台中配置的所有全局参数,如下图
「全局参数」的引用方式和「自定义参数」一致,通过 ${参数名称} 的方式引用,如下图

当任务引用全局参数时,平台将自动识别并添加至运行参数列表;
更多使用技巧
时间基准线
在对自定义参数进行增减之前,需明确取值的时间基准,离线开发支持3种基准线,在右侧的参数面板中分别使用$[] 、${}、 $()3种不同的括号,区分3种时间基准,下面举例说明:
实例的业务日期:2022-05-31 实例的计划运行时间:2022-06-01 12:10:00 实例的实际运行时间:2022-06-01 12:13:31
| 基准线 | 引用方式 | 举例 | |
|---|---|---|---|
| 右侧面板输入 | 参数替换结果 | ||
| 计划时间 | $[] | $[yyyy-MM-dd HH:mm:ss] | 2022/6/1 12:10 |
| 业务日期 | ${} | ${yyyy-MM-dd} | 2022/5/31 |
| 运行时间 | $() | $(yyyy-MM-dd HH:mm:ss) | 2022/6/1 12:13 |
时间增减
基于计划时间取值的时间增减如下,基于业务日期、运行时间的时间增减方式类似,不再列出
后N年:$[add_months(yyyyMMdd,12*N)],输出yyyyMMdd
前N年:$[add_months(yyyyMMdd,-12*N)],输出yyyyMMdd
后N月:$[add_months(yyyyMMdd,N)],输出yyyyMMdd
前N月:$[add_months(yyyyMMdd,-N)],输出yyyyMMdd
后N周:$[yyyyMMdd+7*N],输出yyyyMMdd
前N周:$[yyyyMMdd-7*N],输出yyyyMMdd
后N天:$[yyyyMMdd+N],输出yyyyMMdd
前N天:$[yyyyMMdd-N],输出yyyyMMdd
后N小时:$[hh24miss+N/24],输出yyyyMMddHHmmss
前N小时:$[hh24miss-N/24],输出yyyyMMddHHmmss
后N分钟:$[hh24miss+N/24/60],输出yyyyMMddHHmmss
前N分钟:$[hh24miss-N/24/60],输出yyyyMMddHHmmss
将上述基于计划时间取值的时间增减方式,[] 修改为 {} 或者 () ,可实现基于业务日期或运行时间进行增减
分隔符
在时间增减的基础上,可增加各时间元素之间的分隔符,如下例:
后N年:$[add_months(yyyyMMdd,12*N,-)],输出yyyy-MM-dd,在完成日期加减后,后面可输入 `,-` 其中的 `-` 表示各元素的分隔符,例如$[add_months(yyyyMMdd,12*N,-)]
此规则适用于时间增减的所有格式。
format函数
系统参数结合时间增减,可满足绝大多数场景的参数需求,但一些特殊场景中,需要定义一些特定的输出格式(例如输出MM-dd)、时间增减等信息,此时可使用format函数来支持。
format函数的使用方法:
$[format(yyyyMMddHHmmss+Nunit,'formatString')]
$[]可替换为${}和$(),修改时间基准为业务日期和任务实际运行时间
+Nunit,是在做时间增减
- +表示增加,-表示减少
N表示数量,正整数
unit表示单位,支持y/M/d/H/m/s/w,分别为:年/月/日/时/分/秒/周,N和unit之间无需字符连接
formatString为输出格式,分为3类
- 普通yyyyMMdd等字符:需符合 Joda-Time标准
UnixTimestamp10:10位时间戳格式
ISODate:输出ISODate格式,例如
2020-06-07T16:11:30Z使用举例:
- 业务日期减1天,输出MM-dd格式:
${format(yyyyMMddHHmmss-1d,'MM-dd')}
- 业务日期减1天,输出MM-dd格式:
业务日期减3天,输出MMdd yyyy格式:
${format(yyyyMMddHHmmss-3d,'MMdd yyyy')}计划时间3周后,输出Unix10位时间戳:
$[format(yyyyMMddHHmmss+3w,'UnixTimestamp10')]
format函数各部分区分大小写
适用范围
全局参数、自定义参数适用于全部任务类型,可应用于如下领域:
脚本编写类:SQL/Python/Shell、同步任务脚本模式,脚本整体均可使用;
同步任务(向导):分区、过滤语句、字段映射等
资源上传类:参数输入框
2、任务上下游参数
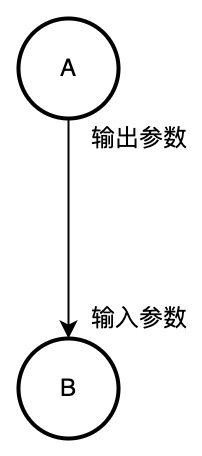
任务运行结束产出的一些结果可能会需要在下游任务中使用,为避免重复计算和维护上的方便,用户可以使用任务上下游参数的功能。
例如A任务是B任务的上游,在A任务中配置的输出参数,可以在B任务中配置输入参数获取到。
支持创建任务上下游参数的任务类型目前有:SparkSQL、HiveSQL、Shell、Python(其中通过资源包引用创建的Python任务不支持设置输出参数)、同步任务(仅有输入参数)、工作流及其上述类型的子节点、Shell on agent任务。
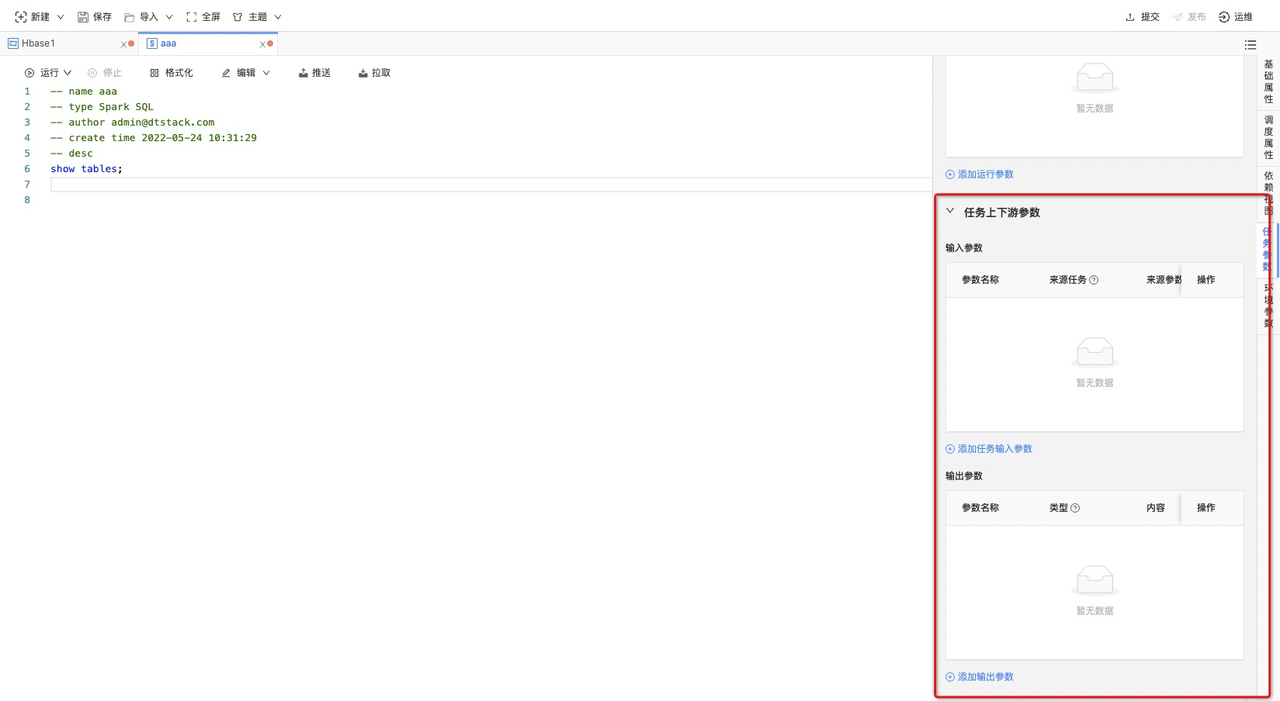
在上述任务的「任务参数 - > 任务上下游参数」中可以分别添加输入参数和输出参数,如下图所示
输出参数
输出参数简介
任务输出参数支持的类型有常量、自定义运行参数和计算结果三种类型。
常量:例如“abc”“12323”等数字或字符串常量
自定义运行参数:例如设置一个“key”,将本任务的自定义运行参数结果传给下游任务。可以将上下游任务共同的参数进行统一管理;
计算结果:对任务的输出表进行取值,例如SQL任务“select a,b from table1 where pt = 20211111”、Python任务“print(a)”、Shell任务“echo a”。平台会把任务输出参数内容写入HDFS文件中。
存储计算结果的文件命名规则:output${参数名称}${任务id}_${计划时间},存储目录:${租户id}/${项目标识}。
同一任务的临时运行/同一实例多次运行会以最新的文件覆盖旧文件。
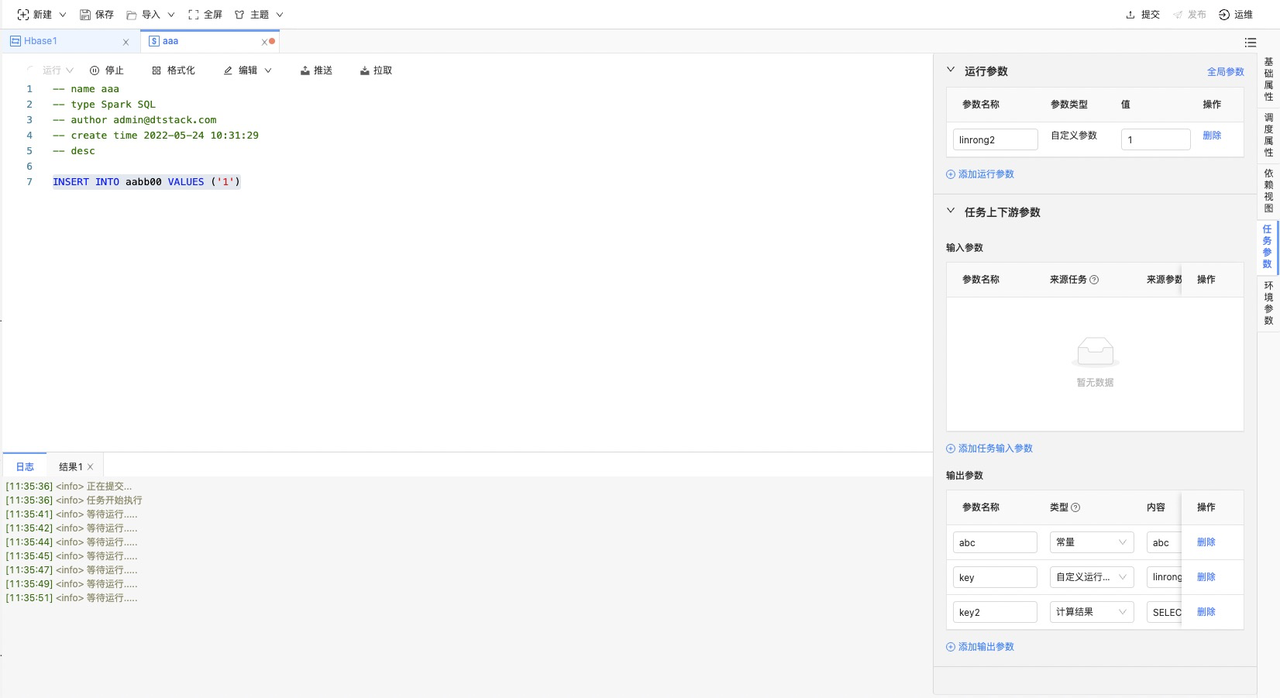
配置输出参数
在「任务参数-> 输出参数」点击「添加输出参数按钮」新增一栏空行,如下图。
参数名称:支持填写1-64字符,只支持大小写英文、数字及下划线;不可与已经配置的任务上下游参数重名;
类型:可选常量、自定义运行参数、计算结果(默认);
内容:根据「类型」选择的结果进行内容填写。
- 类型选择“计算结果”时,“内容”为文本框,可填写1-1024字符,三种任务的输出参数取值填写格式如下:
SQL任务:select 字段 from 表 where 筛选条件
Python任务:print(内容)
Shell任务:echo 内容
- 类型选择“常量”时,“内容”为文本框,1-256字符。
- 类型选择“自定义运行参数”时为下拉框,可选范围为当前任务配置的自定义运行参数。
输入参数
输入参数简介
上游任务配置了输出参数,运行产生结果后,即可在下游任务中使用。
输入参数配置前提:当前任务存在上游依赖任务,且上游任务已配置输出参数并提交。
配置输入参数
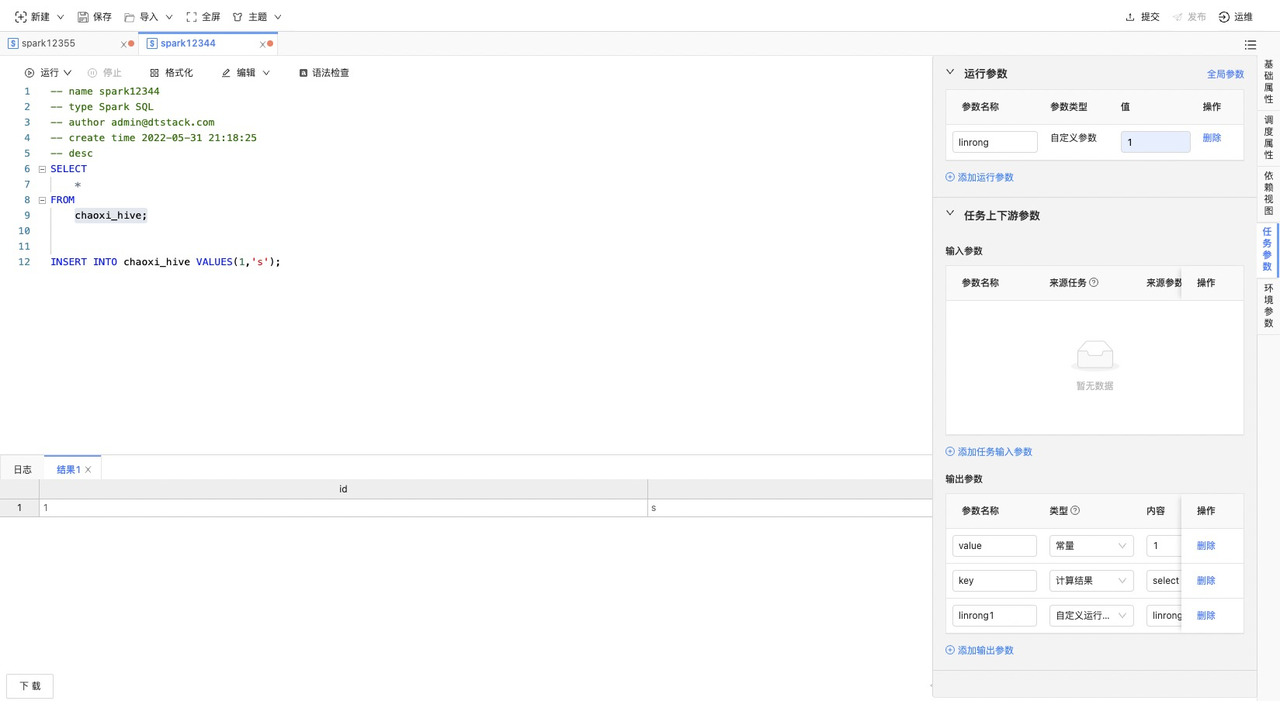
如下图,在“spark12344”任务中分别配置了常量输出参数 “value”、计算结果“key”、自定义运行参数“linrong1”,并进行提交;
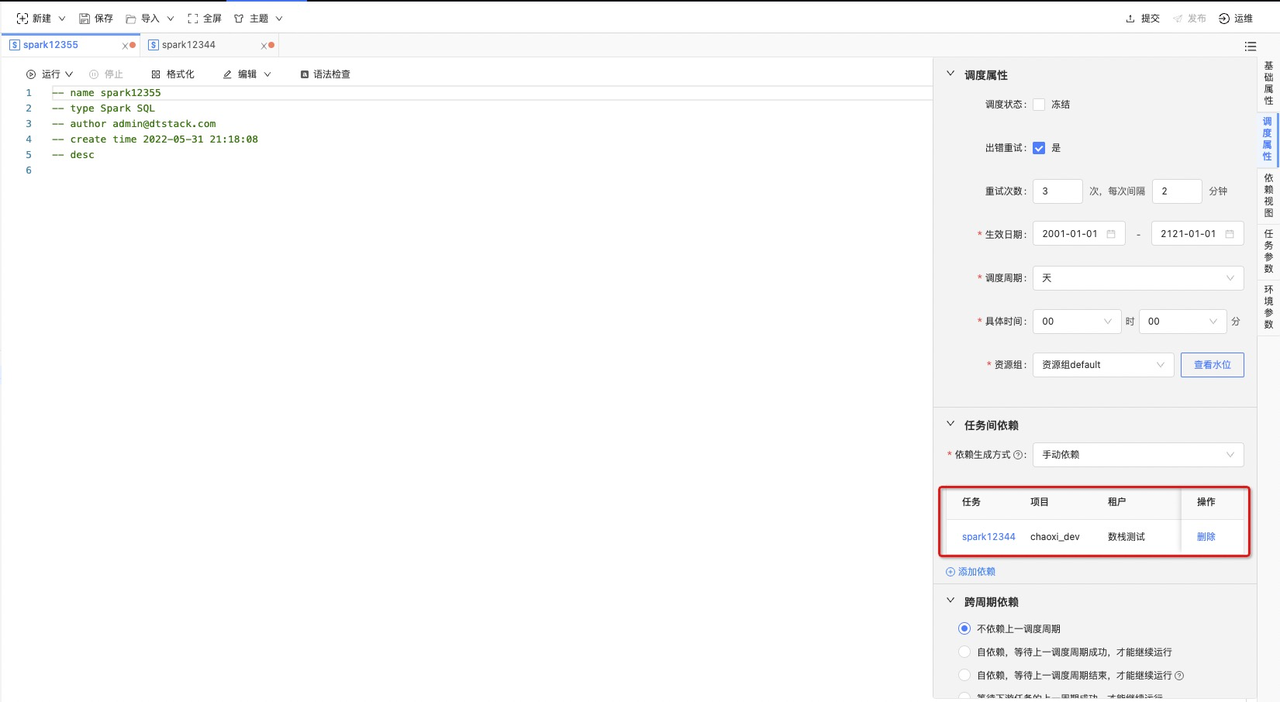
并在‘spark12355’任务中,将‘spark12344’配置为上游依赖任务,如下图
此时可在‘spark1235’任务中「任务参数 -> 任务上线游参数 -> 输入参数」中引入‘spark12344’中的输出参数:在来源任务处选中‘spark12344’,并选中想要引入的输入参数,填写在‘spark12355’中的参数名称,如下图
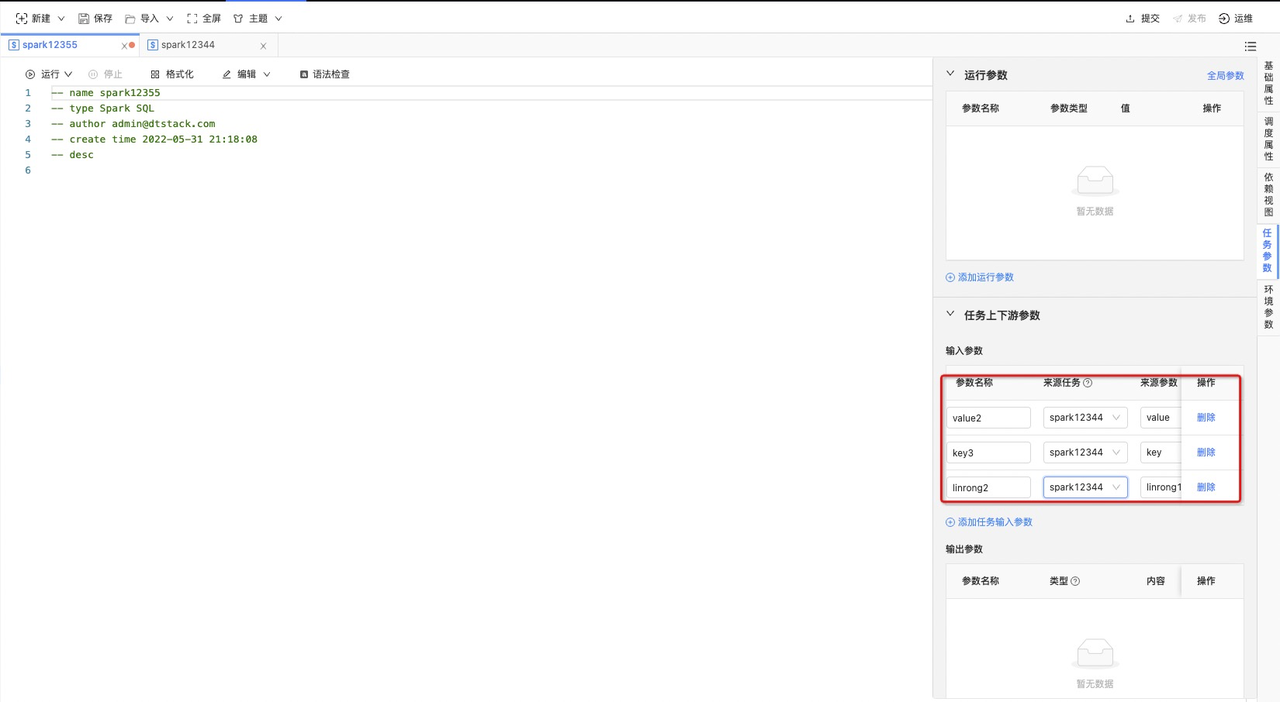
输入参数的在任务中的引用方式和全局参数、自定义参数一致,通过${输入参数名称}的方式引入,如下图所示:
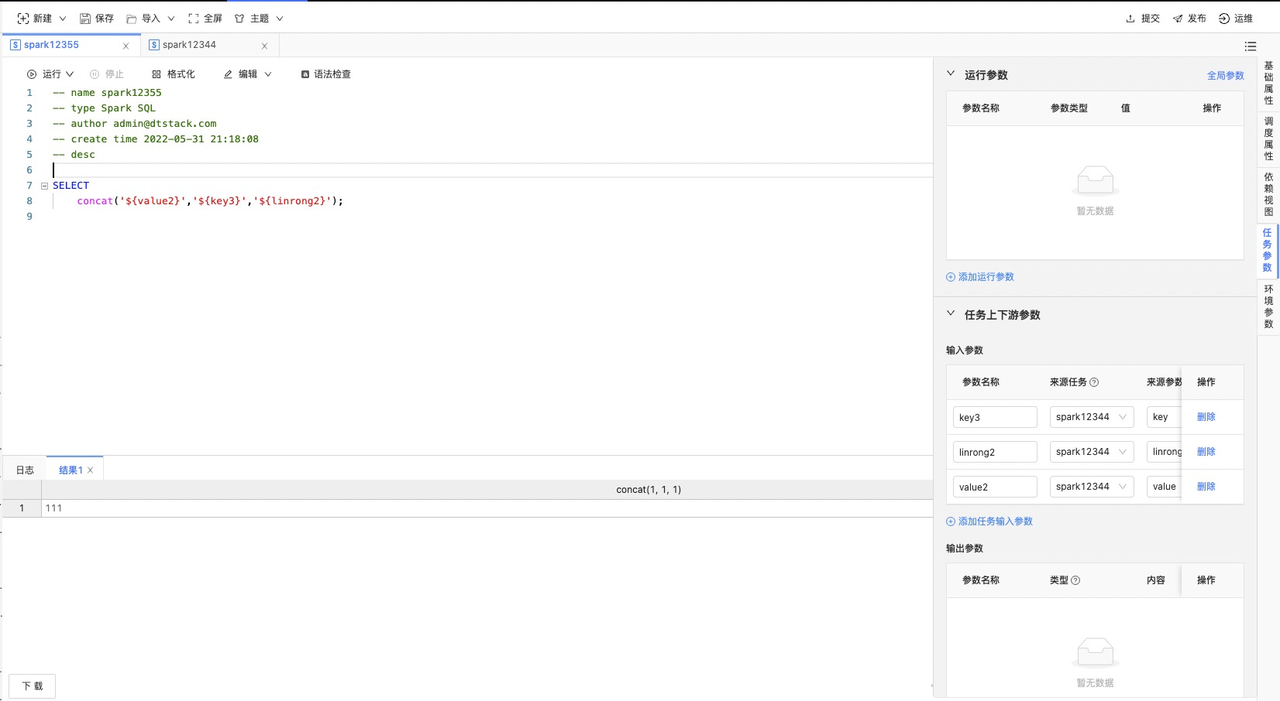
当输出参数为计算结果,select语句查询后包含多个值时,可以通过数组的方式${key}[0][1]进行取值,代表输入参数的第0行,第1列