任务开发
快速开始
本节以创建SparkSQL任务为例,介绍如何创建一个任务并编辑代码内容。更多任务类型的使用请参见 任务类型。
- 新建SparkSQL任务
进入"数据开发"菜单,点击"新建离线任务"按钮,并填写新建任务弹出框中的配置项,配置项说明:
- 任务名称:需输入英文字母、数字、下划线组成,不超过64个字符。
- 任务类型:选择SparkSQL。
- 存储位置:在页面左侧的任务存储结构中的位置。
- 描述:长度不超过200个的任意字符。
点击"保存",弹窗关闭,即完成了新建任务,同时系统自动打开新建的SparkSQL任务。
- 编辑任务代码
任务创建好后,可以在代码编辑器中编写SQL语句(SparkSQL语法与Hive SQL基本相同,与传统关系型数据库的SQL语法有所不同,详细的SQL编辑说明请 Hive SQL的编码说明)。 编写的SQL语句示例如下:
select * from bank_data;
SQLCopied!
查询结果最多只展示1000条数据,可将查询结果下载至本地(仅支持部分SQL类任务),离线开发不支持在页面上下载大量数据。
如果执行的是多个SQL语句,会根据顺序依次下发执行,如果需要在一个session中运行,请参考高级运行一节
SQL编写时支持语法提示:关键字提示、库名提示、表名提示、字段名提示、函数提示,用户编辑SQL代码时,编辑器可实时监测语法错误,并提示红色波浪线进行语法错误提示
- 配置节点任务的调度属性
离线开发提供了丰富的时间周期和依赖关系支持,并提供了基于时间的系统参数和自定义参数支持,请参考 调度属性配置文档。代码和参数配置调试完毕后,一个周期任务需要发布以后才会触发调度系统按配置周期定时产生运行实例并执行代码,提交任务的具体操作请参见发布任务。为使周期任务运行并在每次运行时适应上下文环境,需要配置时间周期和参数。
由于节点任务有周期调度属性,因此内容建议以计算类语句为主,DDL语句建议通过脚本操作,或在语句中使用 IF EXISTS /IF NOT EXISTS 等语法,防止在周期调度过程中产生语法错误
- 运行任务
在当前任务打开的状态下,选择想要执行的部分语句,单击编辑器左上角的「运行」按钮,可触发选定代码执行。如果不选择部分代码,而是直接单击「运行」,则会默认运行当前任务的全部代码。
任务基本管理
新建任务
任何任务都具备如下3个基础属性:
- 任务名称:需输入英文字母、数字、下划线组成,不超过64个字符,项目范围内唯一。
- 任务类型:支持的任务类型请参考 任务类型。
- 存储位置:在页面左侧的任务存储结构中的位置。
- 描述:长度不超过200个的任意字符。
目录管理
在「任务管理」上方的面板中,hover在「操作」icon上,展开操作菜单,点击"新建文件夹"可创建目录,任务保存目录可以以树形结构(文件夹)进行组织,可按多层级的方式进行任务管理与查看。
- 每个目录名称不超过20个字符,支持任意字符
- 同一层级的目录名称不能重复,不同层级的可以重复
- 支持至少5层目录,每一层目录下的直接对象不超过2000个
编辑基本信息
需要修改任务的保存目录时,可在指定任务上点击右键,选择「编辑」,在弹窗中可修改任务的所在目录,同时可以修改任务名称、描述等内容
克隆
在任务右键菜单上,可对任务执行「克隆」或「克隆至工作流」操作:
- 克隆:复制任务,包含代码、各类参数配置,但需注意,目前克隆任务时不会克隆依赖关系;
- 克隆至工作流:将当前任务克隆为某个工作流中的节点(包含代码、各类参数配置,不包含依赖关系)。离线开发不支持将任务直接转换为工作流节点,但可基于此功能进行克隆任务。
任务锁
离线开发通过任务锁的机制防止2个用户同时编辑造成的相互覆盖,具体表现如下:
- 「锁」是按任务划分的,同一时刻的某个任务,只有唯一的一个用户拥有「锁」
- 用户编辑任务之前需要拿到锁,拥有锁的用户才可以编辑任务
- 没有锁的用户,打开任务之后,任务的代码与配置只能查看,不能编辑
- 用户对任务解锁后,他自己获得了此任务的「锁」
- 锁与权限无关,某项目内,除「访客」角色之外的任何用户,可以解锁任何任务
删除
如果在编辑过程中想要放弃一个任务编辑版本,或者周期任务提交后想从调度系统中去掉该任务的自动运行,可在任务的右键菜单中点击「删除」。
- 如果此任务被其他任务依赖(是其他任务的上游任务),则此任务不能被删除,需要先解除依赖关系再进行删除
- 任务删除后,已生成的任务实例不会被删除,但会运行失败
其他操作与功能
- 搜索任务
点击任务编辑栏的「搜索」按钮,或按下Ctrl+P快捷键,通过输入任务名称可搜索并打开任务
- 定位任务
当任务数量很多时,可能在左侧的「任务管理」面板中难以找到当前打开的任务,此时可在「任务管理」上方的面板中,点击「定位」icon,树形结构可快速定位到当前打开的任务所在的位置
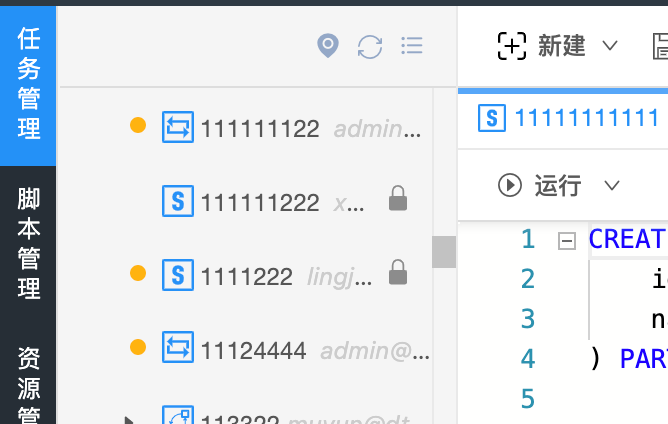
- 任务提交状态
在「任务管理」的树形结构中会自动显示任务的提交状态,未提交的任务前部会显示为黄色圆形icon,如下图所示:
运行任务
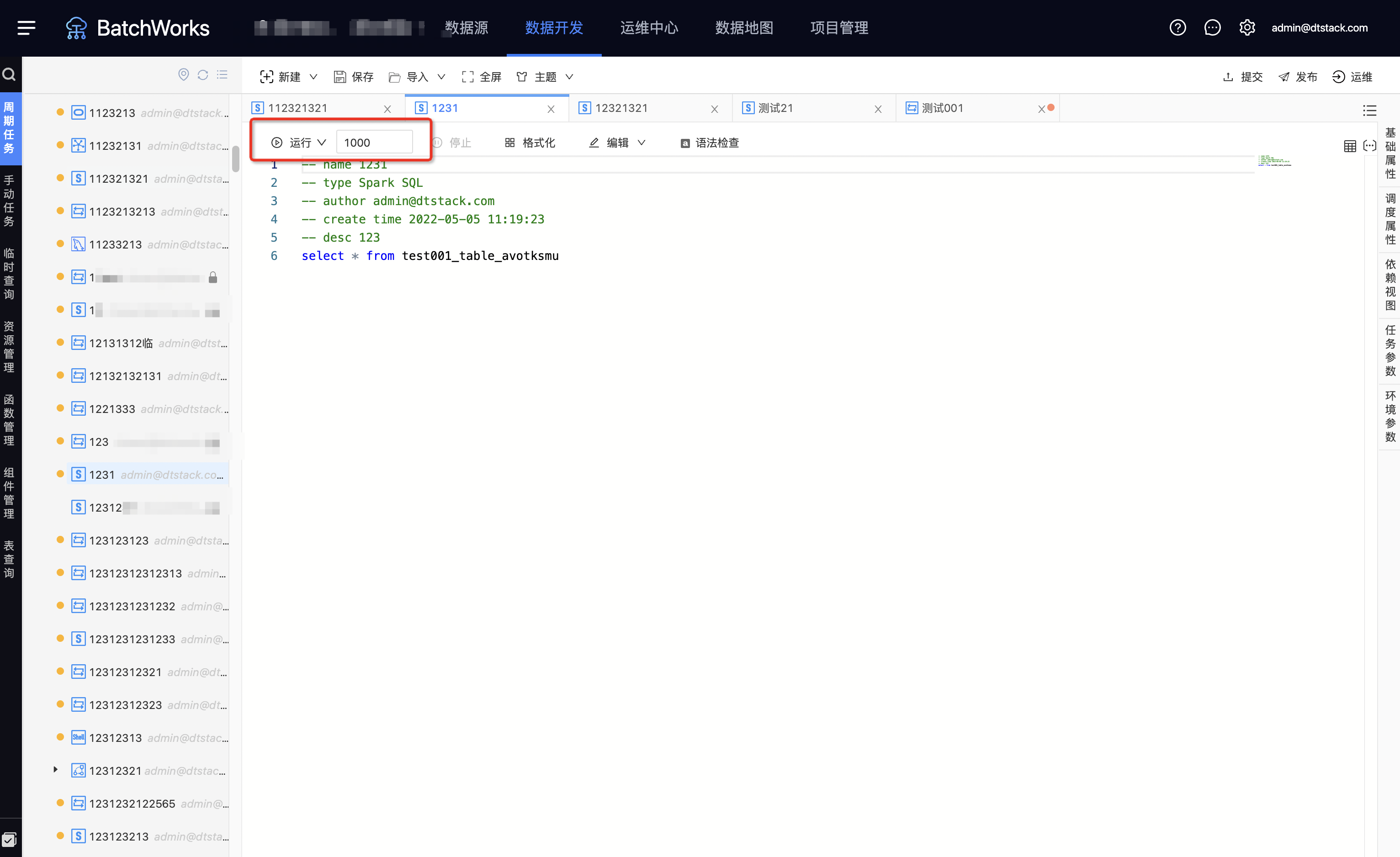
- 普通运行
单击一个SQL任务打开编辑区,选择想要执行的部分语句,然后在操作区单击运行按钮即可触发选定代码执行。如果不选择部分代码,而是直接单击「运行」,则会默认运行当前任务的全部代码。 仅SQL任务支持选定部分代码运行,不支持其他任务类型。
运行侧新增「限制查询条数」输入框,可以对SQL任务的临时查询的查询条数进行限制,如图所示
- 整段运行
高级运行是将选定运行的SQL放在一个session(会话)中运行,即前后的SQL语句存在一定的关联性或参数上的延续性,这样的SQL必须在一个session中运行,例如:set参数(HiveSQL/SparkSQL)、创建临时表等场景。
仅SQL任务支持高级运行、选定部分代码运行
在页面通过按钮点击运行任务时,请勿执行刷新页面跳转到其他页面的操作,刷新或跳转后。若执行了此操作,将会导致正在运行的SQL的状态丢失,无法查看运行状态或日志/结果,且系统会自动将运行的SQL杀死。
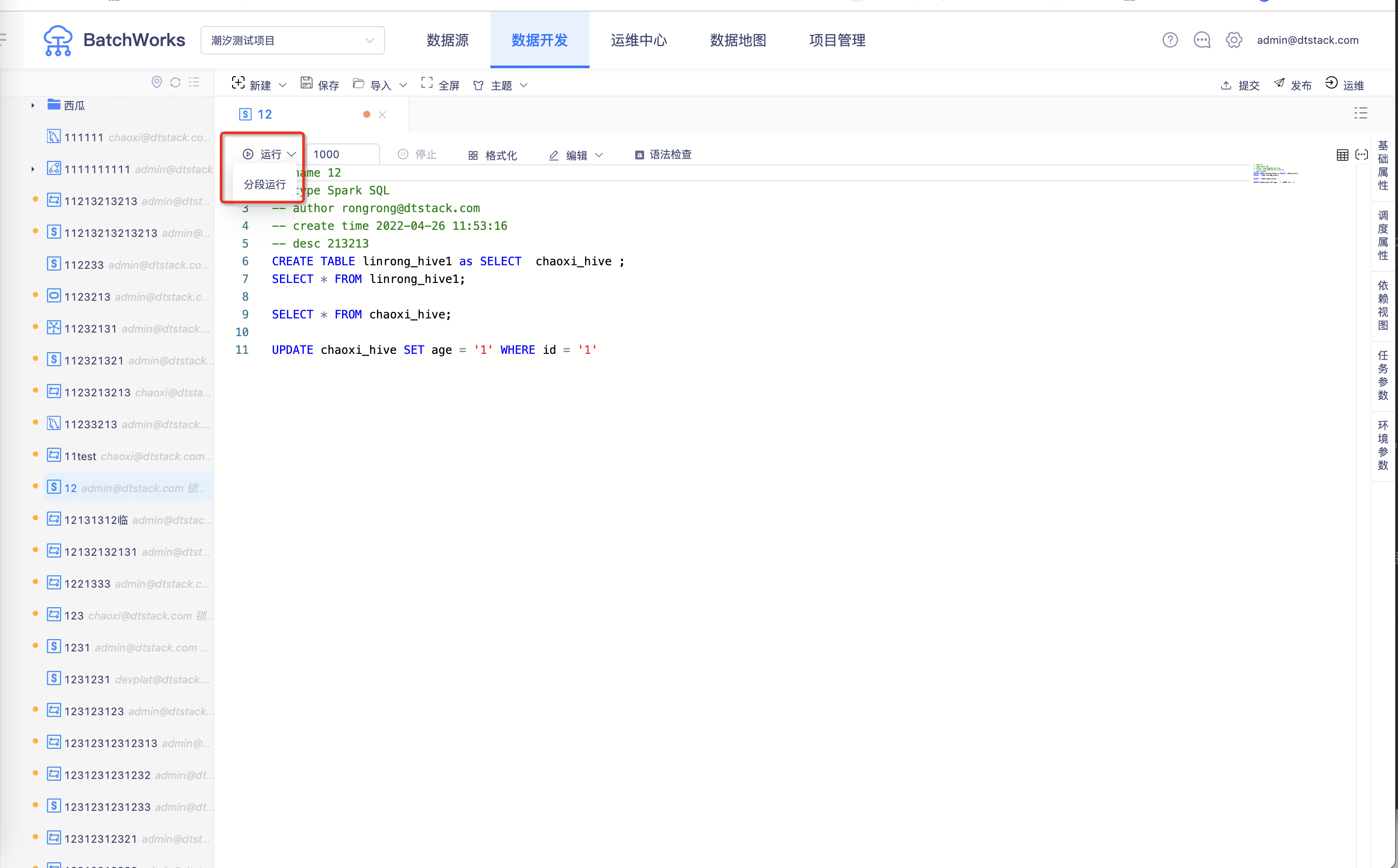
- 分段运行
分段运行时将选定运行的SQL按‘;’进行切割,每一段SQL会单独放在一个session(会话)中进行。
适用范围:临时查询、周期任务和手动任务的临时运行
适用任务:除Shell、Python、Pyspark、Spark、Flink、HadoopMR、同步任务、虚节点、工作流父节点、shell on agent外的所有任务
默认运行方式:rdb分段(GaussDB SQL、Oracle SQL、TiDB SQL、Greenplum SQL、Trino SQL、MySQL、SQL Server、Hana SQL、ADB SQL、HashData SQL、StarRocks),其他整段 (一般情况任务都是要整段提交,RDB这样处理的原因是RDB任务不会提交到yarn上运行,而是通过JDBC直连的,直接进行整段运行可能会导致结果无法及时返回,任务超时报错。)
- 查看日志与结果
任务触发运行后,在编辑区下方会显示日志页,如果有语句的运行结果返回了数据集,则在日志页旁显示结果集的预览,最多可查看1000条查询结果。
无论运行几次,日志页只有一个,仅显示最近一次触发运行的日志信息,之前的日志会被覆盖。结果页可以存在多个,按语句执行顺序依次显示,最多可以显示20个结果页,方便您进行对比数据等操作。
多个语句触发执行时,这些语句将串行执行,日志内容依次显示在日志页中,结果则按每个语句的执行顺序分别显示在不同的结果页中。
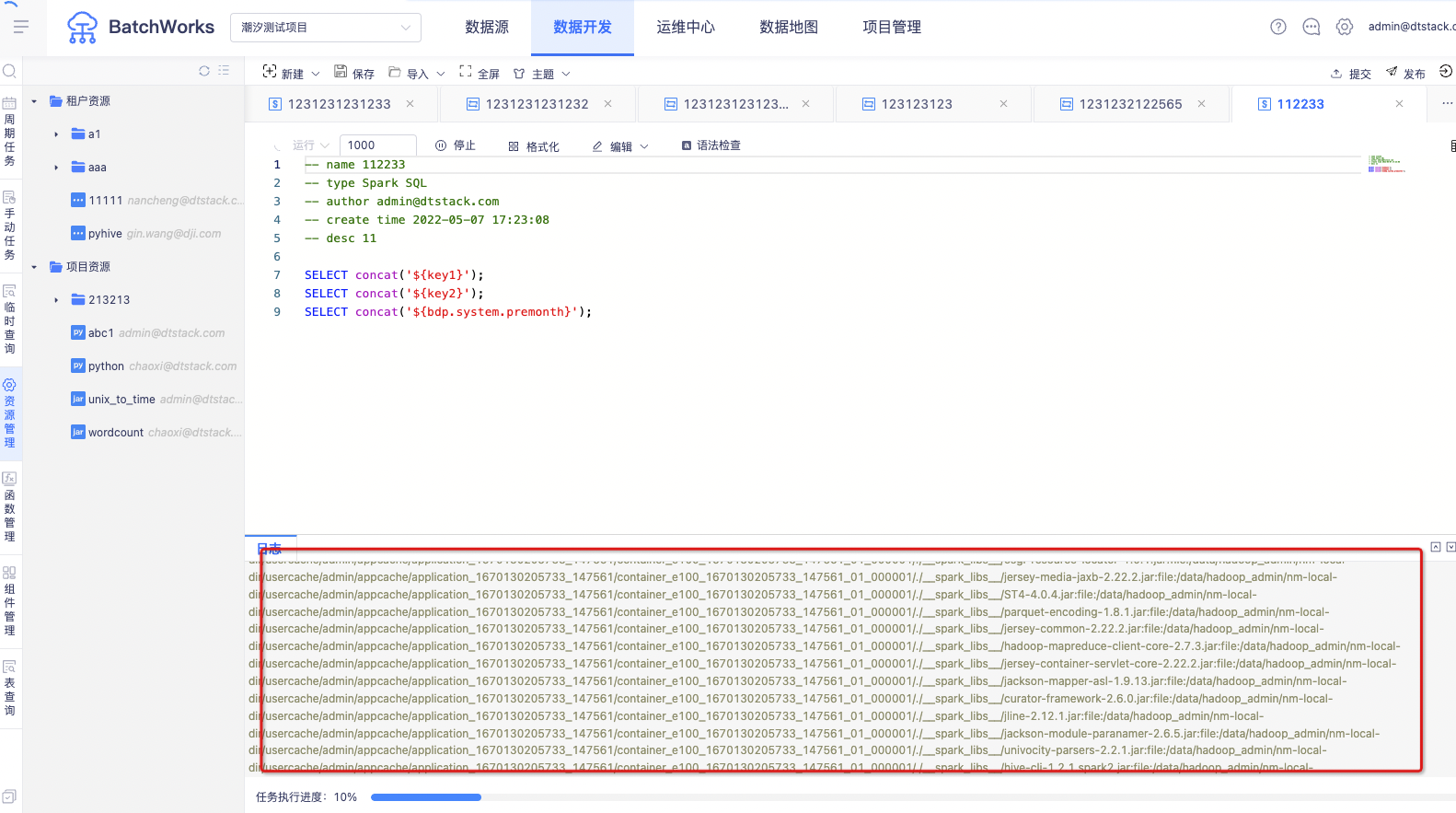
Spark SQL、Hive SQL、数据同步任务的临时运行支持实时打印日志,并展示任务执行进度,如图所示
- 同步任务脏数据
页面运行同步任务时,暂时不支持将脏数据写入脏数据表,必须补数据运行才会写入脏数据。
保存与提交
完成任务编辑后,续点击「保存」按钮,保存任务参数。但保存之后并不会在调度系统中生效,必须点击右上角的「提交」按钮,才会实际生效。提交,是将创建/修改后的任务参数提交至调度引擎生效。
- 任务提交和页面运行权限判断 当前用户在进行任务的页面运行和任务提交时后台将校验用户对于任务中涉及的表的操作是否有对应的全部权限,若否,则将运行或提交失败。 例如,假设任务中有一张表table1,用户A对于这张表只有DQL(查询)权限,但任务中table1相关的操作包含数据的写入或表结构变更,那么用户A在进行该任务的页面临时运行或提交任务时将提示权限不足。 目前仅支持Hive SQL和Spark SQL任务;
提交任务操作,使得一个周期任务的代码和周期配置进入调度系统,从第二天开始,调度系统将根据该任务的周期配置每天生成实例并定时运行,直到该任务被删除,调度系统才会停止为该任务生成实例并运行。
新增或修改任务时,如果当天22:00前发布成功,则在第二天的实例中即可看到结果;如果当天22:00后发布成功,则在第三天的实例中才会看到结果。
一个周期任务只有提交成功后才会进入调度系统,从而使得调度系统按配置周期定时产生实例并运行。
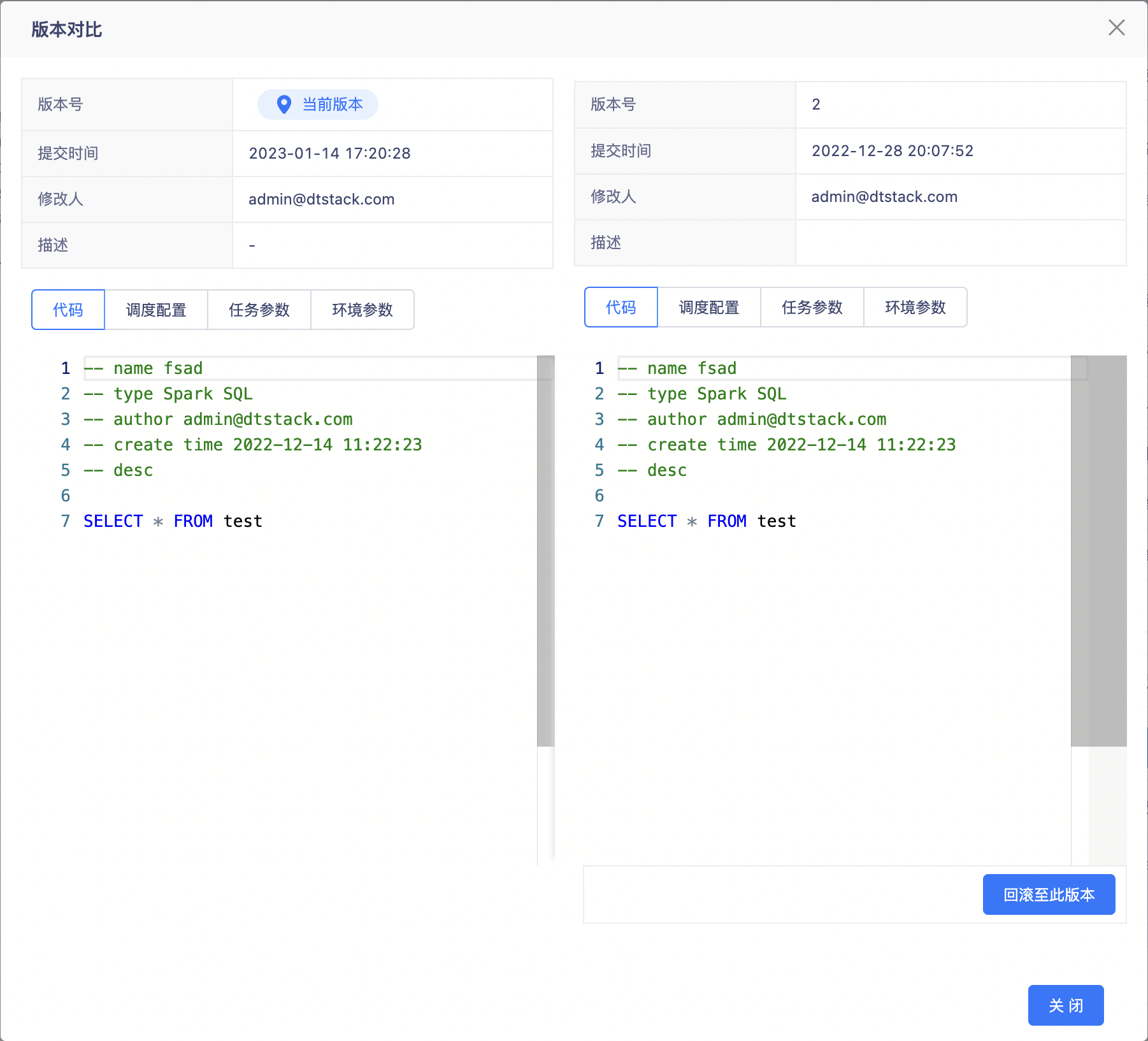
用户的每次提交,会生成一个「版本」,在任务右侧面板中的「任务属性」中,可查看最近50个任务版本,可选中两个版本进行「版本对比」。
点击「回滚至此版本」,会将选中版本的代码、配置等内容覆盖当前任务,但版本回滚不会覆盖「任务依赖」配置,且不会保存任务,用户必须手动确认依赖配置正确性,并手动保存、提交任务才能生效。
编辑任务代码
| Windows | Mac |
|---|---|
| 搜索任务 | Ctrl+P |
| 保存任务 | Ctrl+S |
| 运行 | Ctrl+Enter |
其他快捷键请参考「编辑器->编辑->命令面板」