Kafka Sink
平台支持将采集到的数据实时写入至Kafka Tpoic,供下游实时数据分析使用。
配置项操作和解释
- 操作页面:
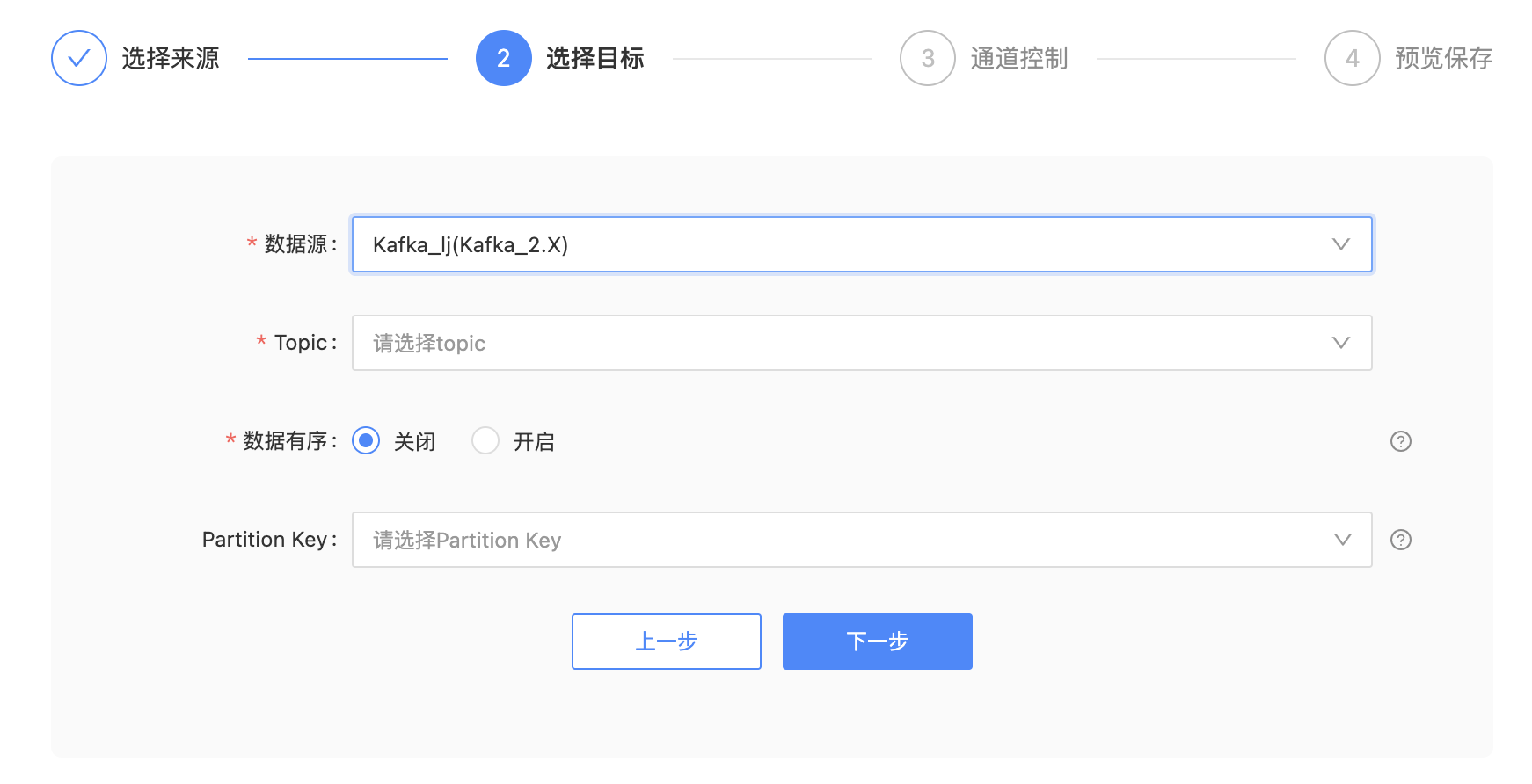
参数解释:
| 配置 | 说明 |
|---|---|
| 数据有序 | 开启后,实时采集将在写入时保证数据的有序性。此时作业读取、写入并发度仅能为1。 |
| Partition Key | 只有采集模式为间隔轮训时,才会显示该配置项。 当指定了partition key之后,具有相同key值的数据在采集时就会被写入同一个partition。(partition key必须包含在采集字段中) |
写入分区的逻辑
当Topic存在多个Partition分区时,平台底层的写入逻辑会根据不同的配置方式而变化,详见如下表格:
| 采集源 | 采集数量 | 数据有序 | 写入设置 | 读取并发度 | 写入规则 |
|---|---|---|---|---|---|
| All | 单表 | 关闭 | 不设置Partition Key | 不限制 | 随机写入所有Topic Partition |
| All | 单表 | 开启 | 不设置Partition Key | 读/写并发度为1 | 默认写入第一个Topic Partition且数据有序 |
| All | 单表 | 关闭 | 设置Partition Key | 不限制 | 根据Partition Key分区写入,同一Key值保证在同一分区内 |
| All | 单表 | 开启 | 设置Partition Key | 读/写并发度为1 | 根据Partition Key分区写入,同一Key值保证在同一分区内且数据有序 |
| 日志采集类数据源 | 多表 | 关闭 | / | 不限制 | 根据 DB.Schema.Table 对数据表进行分区写入,同一表的数据保证写入同一分区内 |
| 日志采集类数据源 | 多表 | 开启 | / | 读/写并发度为1 | 根据 DB.Schema.Table 对数据表进行分区写入,同一表的数据保证写入同一分区内且数据有序 |