数据模型
数据模型作为指标元数据的一部分,为上层指标开发提供数据基础,基于现有的数据模型,开发原子指标时,用户无需调研底层数据关系,直接通过可视化的页面即可配置生成指标,统一了指标数据来源的同时,也降低了指标开发的技术门槛。
通俗地形容,在EasyIndex里,数据模型提供了最基础的事实表和维表之间的基本关系,方便后续创建指标时,直接基于已经固化好的数据关系进行开发。
下面将具体介绍一下数据模型的相关的原理以及操作方式。
模型分类
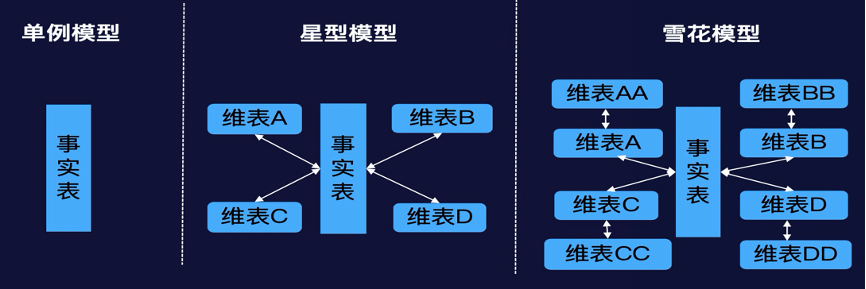
目前数据模型主要采用向导式的配置方式,围绕着维度建模的核心理论,支持常见的单例模型、星型模型和雪花模型:
- 单例模型:单张事实表组成的模型;
- 星型模型:一张事实表,加上一个或多个维度表,事实表和维度表之间通过主键外键相关联,且维度表之间没有关联,从形状上看就像很多星星围着一个星星一样,所以叫星型模型;
- 雪花模型:将星型模型中的某些维度再进一步进行规范,抽取成更细的维度表,让维度表之间也进行关联,那么这个时候,即为雪花模型;
建设过程中,一般会尽可能地避免雪花模型,更多地采用拍平的星型模型。
组成要素
对于EasyIndex来说,数据模型包括表、关系、度量、维度四大组成要素:
- 表:主要以一张事实表和一张或者多张维度表的形式存在,不同类型的表后续计算指标时取数的逻辑会有所不同,具体见下节【表类型】的说明;
- 关系:不管是星型模型还是雪花模型,都会包含多张表,且表之间通过固定的关系形成一个稳定完整的模型;
- 度量:度量列,一个度量对应一个字段,作为后面原子指标的统计来源;
- 维度:维度列,一个维度对应一个字段,作为后面指标统计的维度来源。
基于实际业务情况建立的稳定标准的数据模型,为后续原子指标创建提供便利的同时,也能够规范化指标整体的数据链路,故数据模型稳定后,一般不建议去频繁地更改。
表类型
关于数据模型中表类型的配置,包括普通表、分区表、拉链表三种类型的表,因为数据模型是为后续指标开发提供直接的数据计算来源,而为了保证指标计算结果的准确性,针对不同类型的表,所取的数据范围均有所不同,这边详细说明EasyIndex针对三种类型的表各自对应的处理方式:
- 普通表:说明表里的数据没有时间有效性要求,不管计算什么内容,EasyIndex都会取全表的数据作为基础;
- 分区表:分区表作为数据库存储数据的一种方式,又可以根据实际业务内容分为增量分区表和全量分区表。
- 增量分区表:不会限制数据范围,数据更新时,每次计算选取全部分区的数据作为指标计算的数据来源
- 全量分区表:数据更新时,每次根据分区字段选取对应一个时间分区内的数据作为计算来源
- 拉链表:和分区表一样,相当于表的一种存储方式,它维护了最新状态数据的同时,也维护了历史状态数据,和时间分区一样,相当于做了历史数据留存,但是同时又做了优化,去除了没有变更的数据,既满足了查询数据的历史状态的需求,又节省了存储资源,总的来说拉链表记录了一个事物从开始,一直到当前状态的所有变化的信息。
4.3.0版本中不包括拉链表
模型sql脚本
模型的sql主体主要是‘select from’的形式,其中:
- select后的字段为模型中选择的度量列和维度列对应的字段;
- from后面跟的为模型的主表加上各自的关联表;
模型加工
进入「数据模型」列表,点击「新建模型」即可进入新建模型页面。
设置基础信息
设置模型基本信息,包括模型名称、模型编码、备注。
表关联
模型表可选择表、视图生成模型,表之间可通过left join/right join/inner join进行关联。 单个表/视图需要设置的具体信息规则如下:
- 更新方式:选择增量分区表、非分区表时,模型SQL不会做特殊处理;选择全量分区表时,模型SQL会增加where条件,筛选出业务日期分区内的数据进行后续指标计算;选择拉链表时,模型SQL会增加where条件,筛选出开始、结束时间范围内的有效数据进行后续指标计算。
选择维度
模型设置的维度是后续指标加工过程中用到的所有维度的汇总,此处请选择时间维度、业务维度两类内容。时间维度将用于派生指标的统计周期设置,业务维度将用于后续派生、复合维度设置。同一模型下的维度信息设置不可重复。
选择度量
度量用于后续批量创建原子指标,请至少选择一个度量。